1. Introduction
The survey studies and evaluates three image retrieval systems available on the Internet. Netra, Excalibur and ImageMiner are examined. They are compared to IBM QBIC system.
Netra (W.Y. Ma, 1997) provides content-based image retrieval by color, texture, shape and spatial location. Attributes are represented in feature vectors. The system uses Euclidean difference measure to calculate difference between two attribute feature vectors. Users can search a image using multiple attributes and vary the relative importance of each attribute. Search result is ranked by relevance.
Excalibur system provides similar search functionality as Netra. Attributes are also denoted in feature vectors. It uses Shadow Play algorithm to match images.
ImageMiner (T. Hermes, et.al., 1995) provides content-based image retrieval by color, texture, and shape and objects. The system aims to support conceptual query search. Thus the attributes are represented in textual descriptions. Text matching techniques are used to compute the difference between two descriptions.
Comparing with QBIC (W. Niblack, et.al., 1993) in terms of presentation, Netra offers users more advanced query facilities e.g. drawing the interested shapes on the fly; Excalibur does not have keyword search facility; ImageMiner offers query on high-level abstraction i.e. objects in the image.. But search refinement is not available on any of these systems.
Comparing with QBIC in terms of representation, Netra and Excalibur use the similar attributes representation scheme: feature vectors. ImageMiner uses textual description.
The ideal system should require the least amount knowledge about query
language from users. Refinement search and query by example should always
be there. Advanced query like drawing interested shapes is preferred. At
the same time, the response time is another consideration. Last but not
the least, the system should provide relevance feedback mechanism so that
it can learn from users about the accuracy of search.
![]()
2.
System Descriptions
 ImageMiner jointly developed by University of Bremen and
IBM
ImageMiner jointly developed by University of Bremen and
IBM
Home Page: http://www.informatik.uni-bremen.de/grp/ag-ki/projects/iris/iris-start.html
OR
http://www.software.ibm.com/data/mediaminer/immn0b15.html
Demo: http://www.tzi.uni-bremen.de/BV/imageminer/Gui/queryland.html
ImageMiner automatically analyzes images and generates textual content
descriptions of images. The analysis module processes images in respect
to color, texture and contour features. This information triggers the recognition
of objects, which can also be composed to complex objects. The retrieval
module uses text retrieval products IBM SearchManager to manage the integrated
retrieval of images.
Color attributes are represented in color rectangles.
The system uses a grid with arbitrary size to subdivide the image into
so-called grid elements. For every grid element, a color histogram is computed.
The color that appears most frequently defines the color of the grid element.
Then grid elements with the same color are grouped and the circumscribing
rectangles are determined. The results of color-based segmentation are
called color rectangles, with attributes such as size respective to the
grid size, position respective to the underlying grid size, and the classified
color. Example:
Color2 HOR=mid, VER=up, SIZ=XL, SHP=RECT
COL=BLUE, UL=0--1, LR=44-11, DEN=415-495
Texture attributes are represented in texture rectangles.
The image is segmented by an arbitrary grid. For every grid element, the
system performs some matrix calculations and gets some statistics data.
System is trained to learn a mapping between the statistical value and
the texture. Grid elements with the same texture are grouped together and
the circumscribing rectangle is determined. The results of the texture-based
segmentation are called texture rectangles. Example:
Texture3 HOR=left, VER=mid, SIZ=S, SHP=Path
TEX=clouds, UL=0-3,LR=3-3,DEN=4-4
Shape attributes are represented through contour-based shape
descriptions. The description specifies the coordinate of the middle
point, the size, and the bound coordinate of each region. Example:
Contour0 MID=24-7, SOP=45, UL=0-0,
LR=44-17, SHP=UND
Objects are recognized based on the generated annotations of
the three low level features: color, texture and shape. Object annotations
could be
�
OBJ=sky
OBJ=stone
�
ImageMiner uses a weighed correlation measure to compute similarity
between two feature vectors.
ImageMiner offers a user four levels of detail to combine a query in respect to
![]() Netra: developed at University of California
Netra: developed at University of California
Home Page and Demo: http://vivaldi.ece.ucsb.edu/Netra/
Netra system supports image retrieval by color, contour (shape) and
texture and locations.
Color: The system uses a compact color feature which represent each image region by a subset colors from a color codebook (256-color table). Color feature is represented as
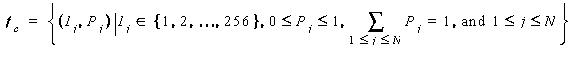
where is I i is the index into the color codebook , P i is the corresponding percentage, and N is the total number of colors in the region. This representation support advanced color query such as "Find all image regions that have 50 % red and 30 % green".
Netra applies distance-based similarity measure. To compute the color distance of image region A and image region B, Netra takes the following steps:
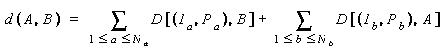
Contour: Netra supports three types of contour representations, which include curvature function, centroid distance, and complex coordinate functions.
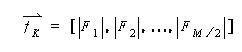
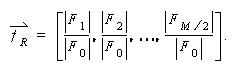
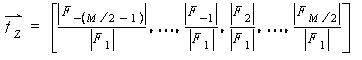
Texture: Netra represents texture feature based on Gabor filters. Gabor filers are considered as orientation and scale tunable edge and line (bar) detectors, and the statistics of these micro features in a given region are often used to characterize the underlying texture information. Mean Character Difference measure is used to compute the difference between to texture vectors.
For a query consisting of more than one of image features, the intersection of the results of search using individual features is computed and then sorted based on a weighted similarity measure. Netra uses an implicit ordering of the image features to prune the search space. The first feature that the user specifies is used to narrow down the space, within which a more detailed search is performed to similarity order the retrieval results.
Netra also allows users to specify spatial location to further disambiguate
the retrievals. For example, consider a search for snow covered mountain
pictures using color and texture. A spatially unconstrained search often
finds regions of ocean surf as such regions also have similar texture and
color. A search constrained to look for solutions only in the upper half
of the image would eliminate or reduce such retrieval instances.
 Excalibur: developed at Excalibur Technologies
Excalibur: developed at Excalibur Technologies
Home Page: http://www.excalib.com/rev2/products/vrw/vrw.html
Demo:
http://vrw.excalib.com/cgi-bin/sdk/cst/cst2.bat
The image retrieval system is used as image search engine by Yahoo,
infoseek, and image surfer. The search system supports search by color,
shape, texture. Each attribute is represented in a feature vector. The
feature vector is constructed with a set of Gaussian derivative filers.
The system uses Shadow Play algorithm to match images. The algorithm
takes an image imprint (extracting feature vector), and then searches a
database to find other images with similar imprint patterns (comparing
distance).
Users can alter the relative importance of the image attributes. Users
also can specify the brightness at each point in the image. Other query
features include the measure of the hue, saturation, and brightness at
each point in the image, and the measure of the ratio of the image's width
to its height.
 QBIC:
developed jointly by University of Davis and IBM
QBIC:
developed jointly by University of Davis and IBM
Home Page and Demo:
http://wwwqbic.almaden.ibm.com/~qbic/qbic.html
QBIC (Query By Image Content) system supports
query on image contents including colors, textures, shapes and locations
of user-specified objects.
Color: QBIC computes the average Munsell (Miyahara, et.al., 1988) coordinates of each object and image, plus a k element color histogram (k is typically 64 or 256) that gives the percentage of the pixels in each image in each of the k colors.
Texture: QBIC's texture featuers are based on modified versions of the coarseness, contrast, and directionality features proposed in (H. Tamura, et.al., 1978). Coarseness measures the scale of the texture (pebbles vs. boulders), contrast describes the vividness of the pattern, and directionality describes whether or not the image has a favored direction or is isotropic (grass versus a smooth object).
Shape: QBIC has used several different sets of shape features. One is based on a combination of area, circularity, eccentricity, major axis orientation and a set of algebraic moment invariants. A second is the turning angles or tangent vectors around the perimeter of an object, computed from smooth splines fit to the perimeter. The result is a list of 64 values of turning angle.
Location: The location features are the x and y centroid of the object.
Weighed Euclidean distance measure is used in similarity matching of two feature vectors. Special similarity measures are adopted for histogram color and turning angle shape.
In QBIC, returned results are ranked and are shown
in order with the best result in the leftmost position, next best in the
next position, and so one. Each image returned is displayed as a reduced
"thumbnail". The thumbnails are active menu buttons that can be clicked
on to initiate the query "Finding images like this one". Each thumbnail
image is also attatched with a link to its full-size image.
![]()
3. Comparisons
We have studied four on-line image retrieval systems, namely ImageMiner, Netra, Excalibur and QBIC. These systems have some common features.
In terms of query types and interface, all systems provide search on
color, shape, texture or combination of them. Retrieved images are also
ranked by relevance. Query by graphical exmapleall is available in all
systems. However, all these systems do not support refinement search. Users
cannot search images in a subset of database images. This is partcially
because refinement search requires a large temporary storage for each search
session and it seems impossible for Internet applications since number
of search sessions is unpreditcable. Moreover, all systems do not have
a facility to allow users to provide relevance feedback to the system.
Especially for those textual descritpion-based image retrieval systems
like ImageMiner, user relevace feedback is important for updating the image
description to improve subsequent retrieval.
In terms of attribute representation and similarity matching, Netra,
Excalibur and QBIC presents a similar scheme which is very different from
ImageMiner. The former three systems use feature vector to represent the
attributes. Distance-based measure is applied to similarity matching in
these systems. For ImageMiner, attributes are represented in textual content
descriptions and similarity matching is computed in Correlation measure.
ImageMiner, Netra, Excalibur and QBIC also have some distinct features.
In terms of attribute representation and similarity matching, Netra
uses Eculidean metric to compute distance for Color and Shape attribute
and adopts Mean character distance measure for Texture. Excalibur and QBIC
uses Euclidean metric measure for all attributes.
Netra and Excalibur allow users to vary the importance of each search
attribute but the way they do it is different. Netra implicitly uses the
order of attributes user specifies whereas in Excalibur users can explicitly
specify the weight percentage of each attribute.
In QBIC, search results are displayed in thumbnails which can be clicked to see the full-size image. It also supports search by keywords and URL. ImageMiner on-line demo does not provide text search but the vendor promises support for this functionality. QBIC also supports search by color layout and color percentage search such as "find all image regions that have 70 % blue and 20 % green".
Netra supports search by location to further disambiguate the retrievals. Netra also supports search by color percentage.
In Excalibur, users can search images by brightness, hue and saturation, and ratio of image's width to height.
ImageMiner supports conceptual query (query on objects in the image)
thus semantics of the image can be quried to some degree. ImageMiner also
supports search in 17 languages thus can be widely used across countries.
In terms of implementation, ImageMiner and Netra demos are java applet-based
whereas QBIC and Excalibu uses CGI program. As we know, CGI-based client-server
communication enforces browser screen refresh at each client request. But
applet-based program make the page retain the same during interaction with
users. Refreshing may disturb user attentions. The problem is espeically
serious in QBIC system.
![]()
4. Conclusion
This survey studies and evaluates four image retrieval systems on Internet. They are QBIC, ImageMiner, Netra and Excalibur. Image retrieval on these systems are content-based and similarity-based. Common content attributes including color, texture and shape are supported by all attributes. The survey examines attribute representation, similarity matching formular in each system. The survey also study the query type and presentation interface offered by these systems. These systems are compared with each other to illustrate the state-of-art in current image retrieval systems on Internet.
Basd on these studies, I think an idea system should provide, or in other words, future image retrieval system developement should consider, the following features:
Query Based on Spatial Relationship
Current systems have focused on the representation of individual image
regions and search strategies for single region queries. The next immediate
goal should be integrating spatial relationship between regions into the
image retrieval system. ImageMiner seems to provide this functionality
but it assumes that the individual objects can be matched exactly and con-
centrate only on the matching of their spatial relationships. This
is usually not the case for most image database applications where each
region is represented by a set of image features and exact match between
features is not a reasonable assumption. An ideal system should integrate
the region features and their spatial relationship into a unified representation.
Such a strategy could support for high-level object based queries.
User's Relevance Feedback for Query Refinement
Modifying the retrieval results based on user feedback is another interesting consideration. An image retrieval system should be able to incorporate relevance feedback from users. One idea (W. Y. Ma, 1997) is to utilize a nonlinear mapping to learn the appropriate transformation from the original feature space to the new space where visually similar patterns will cluster together. This mapping function can be designed such that it can be dynamically adjusted or refined based on the user relevance feedback to improve retrieval performance.
Visual Thesaurus
Combine various low-level image attributes (color, texture, shape, spatial
relationship, etc.) to construct a
visual thesaurus which can index image database based on the co-occurrence
properties
among these image attributes.
Besides these considerations, other factors that make an image retrieval system perfect could be:
5. Acknowledgements
Special thanks to Zhang Yi and Zhao Xiangpeng who both helped me locate
the available on-line image retrieval systems and their reference sources.
![]()
6. References